在當今競爭激烈的商業環境中,企業形象已成為區分品牌、贏得客戶信任和市場份額的關鍵因素。深圳,作為中國的創新之都和設計前沿城市,匯聚了眾多專業的企業形象設計公司與VI策劃機構,它們共同助力企業構建獨特、統一且富有感染力的品牌形象。
企業形象設計是一個系統工程,它遠不止于一個logo或一套色彩方案。它涵蓋了企業的理念、文化、行為規范以及視覺表達的整體融合。而視覺識別系統(Visual Identity,簡稱VI)則是其中至關重要的一環,是將企業理念轉化為具體視覺符號的核心工具。一套優秀的VI設計,能夠確保企業在各種媒介和場景下傳遞出一致、專業且易于識別的信息,從而在消費者心中建立起穩固的品牌認知。
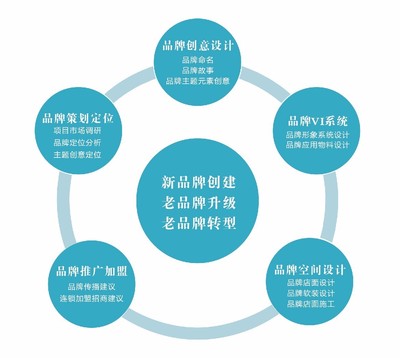
深圳的企業形象設計公司,憑借其國際化視野、創新思維和深厚的市場洞察力,在VI策劃設計領域獨樹一幟。這些公司通常遵循一套嚴謹的策劃與設計流程:
- 深入調研與策略定位:這是所有成功設計的起點。專業的設計團隊會深入理解企業的行業背景、市場定位、核心價值、目標受眾以及競爭對手情況。通過分析,明確品牌希望傳達的核心信息與情感,為后續的視覺設計奠定堅實的策略基礎。
- 核心要素設計(基礎系統):這是VI系統的靈魂所在。主要包括:
- 標志(Logo)設計:創造獨特、簡潔、易記且具有延展性的企業標識,它是品牌最核心的視覺資產。
- 標準字與標準色:定義品牌專用的字體體系與色彩系統,確保視覺表達的規范性與情感一致性。
- 輔助圖形與品牌符號:開發能夠強化品牌識別、增加應用靈活性的視覺元素。
- 應用系統設計與規范:將基礎元素系統地應用于企業實際接觸點,形成一套完整的使用手冊。這包括:
- 辦公事務系統:名片、信紙、信封、PPT模板等。
- 環境導視系統:辦公室標識、廠房標牌、門店裝修等。
- 宣傳推廣系統:網站、社交媒體界面、宣傳冊、廣告、禮品包裝等。
- 服裝與車輛系統:員工制服、公務車輛外觀等。
- 落地執行與資產管理:協助企業將VI系統在實際中貫徹實施,并提供規范的電子文件庫,確保品牌形象在長期使用中不走樣。
選擇一家優秀的深圳VI策劃設計公司,企業獲得的不僅僅是一套設計圖稿,更是一套能夠驅動業務增長的戰略性工具。它能夠:
- 提升品牌辨識度與專業度:在紛繁的市場中脫穎而出,給人留下深刻、專業的印象。
- 增強內部凝聚力:統一的形象讓員工產生歸屬感與自豪感,提升團隊士氣。
- 降低傳播成本:一致的視覺輸出使每一次傳播都累積品牌資產,提高營銷效率。
- 支撐業務擴張:一套具有前瞻性和系統性的VI,能夠輕松適應企業未來的多元化發展與市場拓展。
因此,對于任何有志于在深圳乃至全國全球市場建立持久影響力的企業而言,投資于專業的企業形象策劃與VI設計,并非一項可有可無的支出,而是一項關乎品牌未來價值的戰略投資。通過與深諳市場脈搏的設計伙伴合作,企業能夠將無形的理念轉化為有形的競爭力,在商業浪潮中樹立起一座堅實的品牌燈塔。